Can AI help predict the impact of an ad or video on consumer behavior? Or can AI be used to understand what feelings creative assets trigger or whether they fit into a brand’s communication? Moreover, can AI give us deep insights into consumer perception without directly talking to them?
from Marketing AI Institute | Blog https://ift.tt/XPU6H2z
via IFTTT
We are excited to announce a new embedding model which is significantly more capable, cost effective, and simpler to use. The new model, text-embedding-ada-002, replaces five separate models for text search, text similarity, and code search, and outperforms our previous most capable model, Davinci, at most tasks, while being priced 99.8% lower.
Embeddings are numerical representations of concepts converted to number sequences, which make it easy for computers to understand the relationships between those concepts. Since the initial launch of the OpenAI /embeddings endpoint, many applications have incorporated embeddings to personalize, recommend, and search content.
You can query the /embeddings endpoint for the new model with two lines of code using our OpenAI Python Library, just like you could with previous models:
Stronger performance. text-embedding-ada-002 outperforms all the old embedding models on text search, code search, and sentence similarity tasks and gets comparable performance on text classification. For each task category, we evaluate the models on the datasets used in old embeddings.
Unification of capabilities. We have significantly simplified the interface of the /embeddings endpoint by merging the five separate models shown above (text-similarity, text-search-query, text-search-doc, code-search-text and code-search-code) into a single new model. This single representation performs better than our previous embedding models across a diverse set of text search, sentence similarity, and code search benchmarks.
Longer context. The context length of the new model is increased by a factor of four, from 2048 to 8192, making it more convenient to work with long documents.
Smaller embedding size. The new embeddings have only 1536 dimensions, one-eighth the size of davinci-001 embeddings, making the new embeddings more cost effective in working with vector databases.
Reduced price. We have reduced the price of new embedding models by 90% compared to old models of the same size. The new model achieves better or similar performance as the old Davinci models at a 99.8% lower price.
Overall, the new embedding model is a much more powerful tool for natural language processing and code tasks. We are excited to see how our customers will use it to create even more capable applications in their respective fields.
Limitations
The new text-embedding-ada-002 model is not outperforming text-similarity-davinci-001 on the SentEval linear probing classification benchmark. For tasks that require training a light-weighted linear layer on top of embedding vectors for classification prediction, we suggest comparing the new model to text-similarity-davinci-001 and choosing whichever model gives optimal performance.
Check the Limitations & Risks section in the embeddings documentation for general limitations of our embedding models.
Examples of Embeddings API in Action
Kalendar AI is a sales outreach product that uses embeddings to match the right sales pitch to the right customers out of a dataset containing 340M profiles. This automation relies on similarity between embeddings of customer profiles and sale pitches to rank up most suitable matches, eliminating 40–56% of unwanted targeting compared to their old approach.
Notion, the online workspace company, will use OpenAI's new embeddings to improve Notion search beyond today's keyword matching systems.
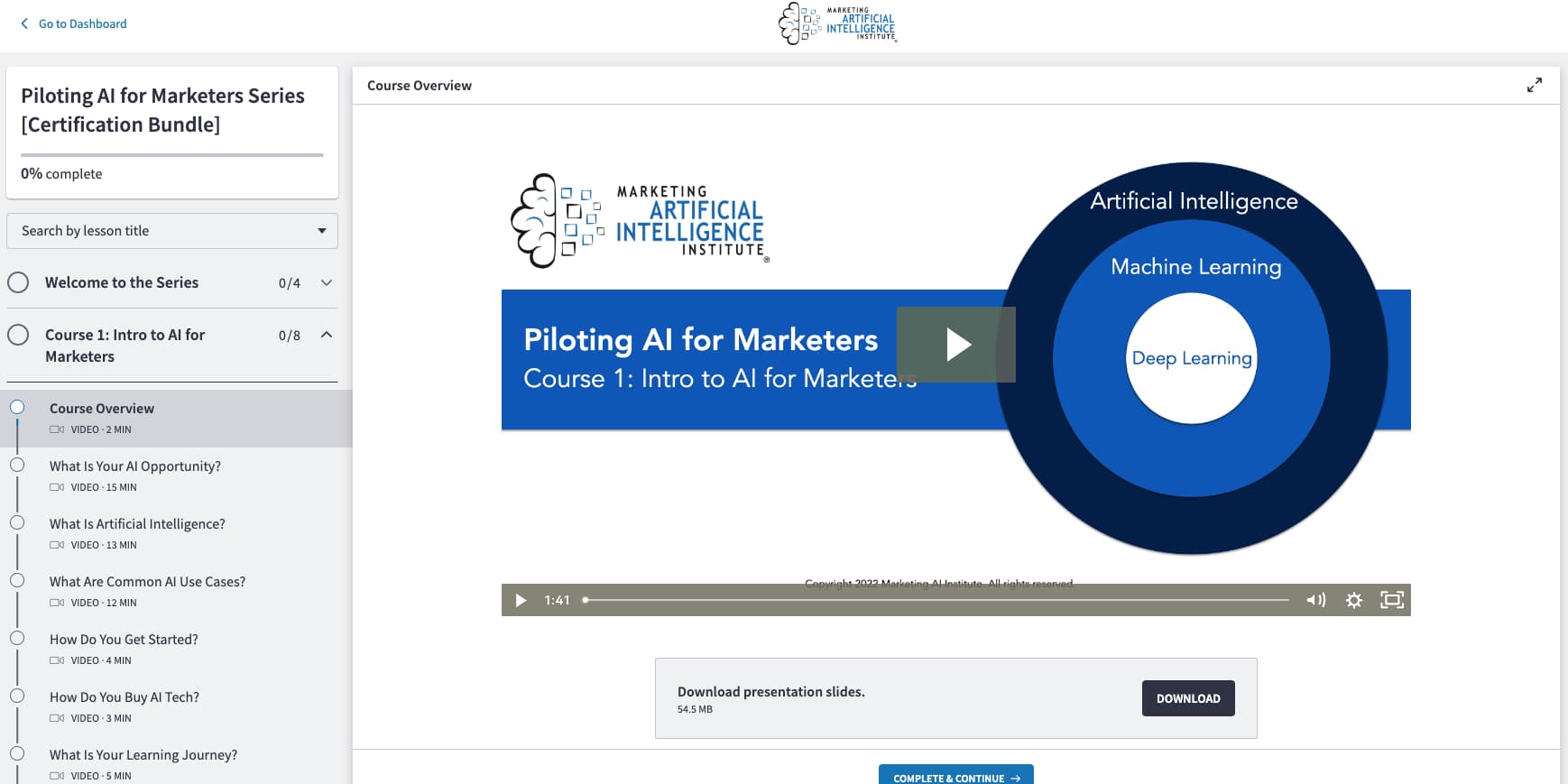
Today, we’re introducing Piloting AI for Marketers, a series of 17 on-demand courses designed as a step-by-step learning journey for marketers and business leaders to increase productivity and performance with artificial intelligence.
from Marketing AI Institute | Blog https://ift.tt/V52BLTQ
via IFTTT
McKinsey’s annual survey, Lensa AI, and Paul’s LinkedIn post about software companies take center stage on this week’s Marketing AI Show podcast episode.
from Marketing AI Institute | Blog https://ift.tt/sgTeXKk
via IFTTT
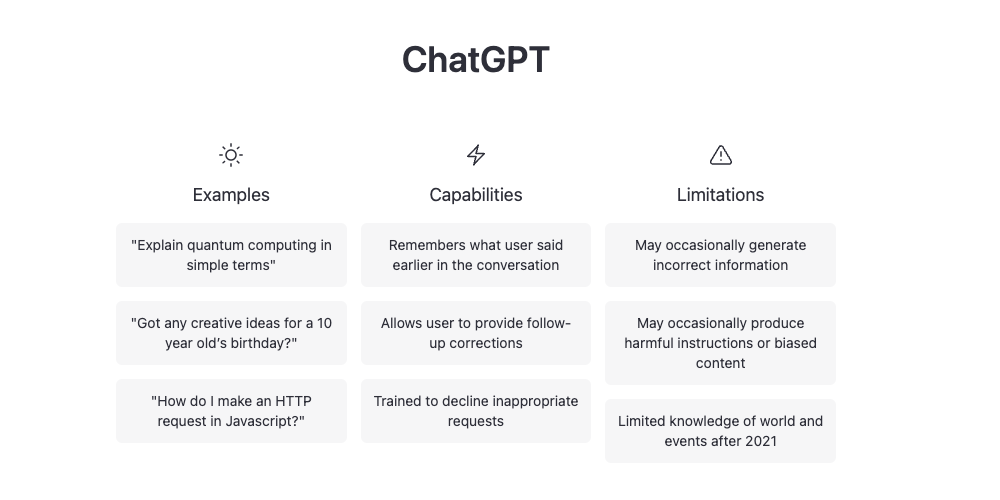
If you’re in content marketing, marketing, artificial intelligence, or an active LinkedIn member, there’s no doubt OpenAI’s ChatGPT has made its way into a conversation or your social feed.
from Marketing AI Institute | Blog https://ift.tt/PvZFUtA
via IFTTT
Lensa, an all-in-one image-editing app with facial retouching capabilities, is taking over social media feeds with its eye-catching AI-generated images and avatars.
from Marketing AI Institute | Blog https://ift.tt/jlKdaLZ
via IFTTT
You’ve piloted a small test case using artificial intelligence. Excellent! Now you’ll need to show the success of your first test case. Long-term buy-in is dependent on the success of the programs that have been completed, so measurement and analytics are essential to set up before the launch of any program.
from Marketing AI Institute | Blog https://ift.tt/1pyXjsA
via IFTTT
Do you spend a lot of time doing voice overs for videos, narrating content, or recording voice work for ads? AI can help you do it faster, easier, and cheaper.
from Marketing AI Institute | Blog https://ift.tt/vfthcgi
via IFTTT
I just tested ChatGPT from OpenAI. My immediate reaction after five minutes is that the marketing profession, business world and society are not even close to ready for what is about to happen as a result of rapid advancements in artificial intelligence.
from Marketing AI Institute | Blog https://ift.tt/U5R82V3
via IFTTT
![Boosting Creative Effectiveness and Marketing ROI with AI and Neuroscience [Video]](https://www.marketingaiinstitute.com/hubfs/YouTube%20-%20Saswito.jpg)







![[Marketing AI Show Episode 26]: McKinsey's State of AI 2022, Lensa AI, and AI Will Eat Software Companies](https://www.marketingaiinstitute.com/hubfs/ep%2026%20cover.jpg)
![[The Marketing AI Show Episode 25] ChatGPT, What It Means for Marketing, and How It Will Change Business As We Know It](https://www.marketingaiinstitute.com/hubfs/ep%2025%20cover.jpg)