
Google just announced some huge AI updates…
![]()
from Marketing AI Institute | Blog https://ift.tt/84YcnCR
via IFTTT
Google just announced some huge AI updates…
![]()
from Marketing AI Institute | Blog https://ift.tt/84YcnCR
via IFTTT

AI companies like OpenAI are coming under fire for how AI tools are trained…
![]()
from Marketing AI Institute | Blog https://ift.tt/7vnBbYX
via IFTTT
![[The Marketing AI Show Episode 44]: Inside ChatGPT’s Revolutionary Potential, Major Google AI Announcements, and Big Problems with AI Training Are Discovered](https://www.marketingaiinstitute.com/hubfs/ep%2044%20cover.png)
Episode 44 of the Marketing AI Show with Paul Roetzer and Mike Kaput covers stunning results from ChatGPT plugins, major Google AI announcements, problems with AI training, and more.
Listen or watch below—and keep scrolling for a summary of the show.
![]()
from Marketing AI Institute | Blog https://ift.tt/QxWByit
via IFTTT

I shared an opinion last week on LinkedIn (original post here) about the potential impact of AI on knowledge workers and the economy. The basic premise was that we are looking at the possibility of millions of jobs being impacted in the next 1 – 2 years.
![]()
from Marketing AI Institute | Blog https://ift.tt/UbAJmHr
via IFTTT

Amazon just made a big play into the generative AI space, making them another serious contender in the AI arms race.
![]()
from Marketing AI Institute | Blog https://ift.tt/DTZByJx
via IFTTT

Generative AI is ushering in dramatic changes in content marketing. The potential to save time and resources, no doubt, is a major part of its appeal. But this technology comes with complexities and challenges, including data quality and bias, to ethical considerations.
![]()
from Marketing AI Institute | Blog https://ift.tt/uyLpQ6v
via IFTTT
![[The Marketing AI Show Episode 43]: AWS Gets Into the Generative AI Game, AutoGPT and Autonomous AI Agents, and How AI Could Impact Millions of Knowledge Workers Sooner Than You Think](https://www.marketingaiinstitute.com/hubfs/ep%2043%20cover.png)
This week’s episode of The Marketing AI Show, hosted by Paul Roetzer and Mike Kaput, talks about big generative AI announcements from AWS, the impact of AutoGPT, and how AI could impact millions of knowledge workers sooner than we think.
![]()
from Marketing AI Institute | Blog https://ift.tt/SUYfhjH
via IFTTT
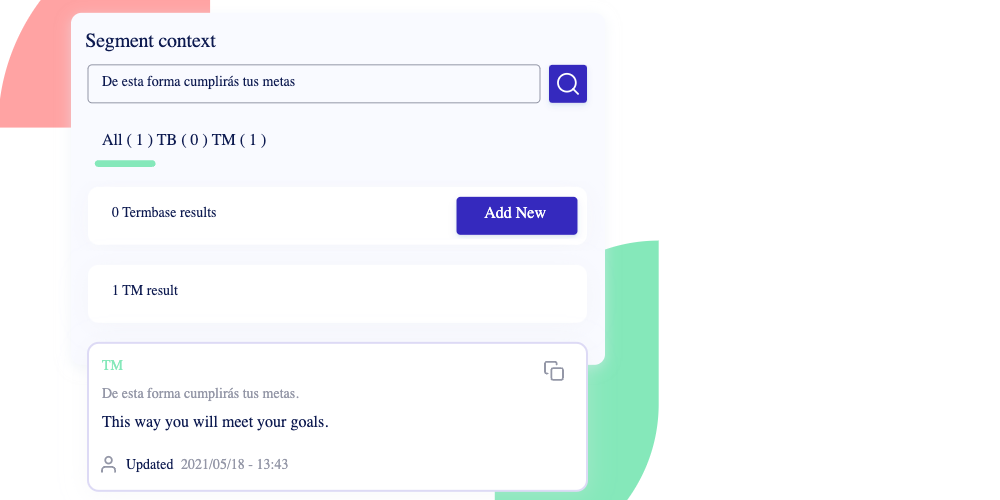
Lilt is an AI-powered platform that translates marketing collateral and campaigns into as many languages as needed to create a truly global customer experience.
The company’s patented translation engine uses AI and machine learning to give human translators adaptive translation suggestions across localizations.
We spoke with Andy Jolis, CMO at Lilt, to learn more about this AI-powered marketing solution.
![]()
from Marketing AI Institute | Blog https://ift.tt/BI8zFck
via IFTTT
This initiative is essential to our commitment to develop safe and advanced AI. As we create technology and services that are secure, reliable, and trustworthy, we need your help.

ChatGPT has been banned in Italy, but that might be just the start of its problems.
![]()
from Marketing AI Institute | Blog https://ift.tt/WwoPb6v
via IFTTT